Nucleic Acid Types
There are two types of nucleic acid: deoxyribonucleic acid (DNA) and ribonucleic acid (RNA). Both play a central role in every function of every living organism. Nucleic acids have similar basic structures with important differences. They are composed of monomer nucleotides connected like links in a chain to form nucleic acid polymers. Nucleotides consist of a nucleoside (the combination of a pentose monosaccharide molecule and a nitrogenous base) and a phosphate group. The difference between RNA and DNA lies in a single nitrogenous base and a single atom of oxygen within a sugar molecule.
DNA
DNA is the genetic blueprint of a living organism in which all information is stored and from which all information can be passed on. It has a distinctive double-helix form – two single strands which entwine around each other. A strand of DNA is much longer than that of a singular strand of RNA. This is because every strand of DNA in every cell contains the blueprint for the entire organism. Deoxyribonucleic acid is found primarily in the nucleus. However, DNA in a much shorter version can also found in the mitochondria (mtDNA) where it supplies the genes necessary for adenosine triphosphate production, the most important source of cellular energy.
Any cell which has a nucleus contains nucleic acid in the form of DNA. There are various exceptions to the rule. Some cells lose their nucleus and DNA during the aging process, such as mature red blood cells, corneocytes, and keratinocytes. Blood platelets are sometimes mentioned as containing neither nucleus nor DNA; however, platelets are fragments of megakaryocytes and not considered to be actual cells. Single-cell organisms (prokaryotes) such as bacteria have no nucleus but contain loose strands of DNA in the cytoplasm, as shown below.
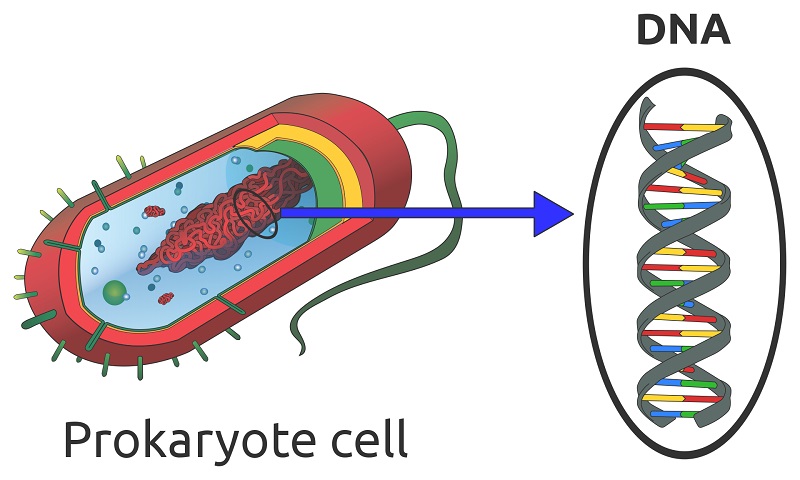
Nucleic Acid Structure of DNA
The structure of DNA, a globally recognized double-helix, is based upon the two strands of a sugar-phosphate backbone held together by nitrogenous base spindles. DNA contains four nitrogenous bases, or nucleobases: adenine, thymine, cytosine, and guanine. These are naturally occurring compounds which give each nucleotide its name, and are divided into two groups – pyrimidines and purines. While the pyrimidines cytosine, thymine and uracil (see RNA) are small, single-ringed constructions, adenine, and guanine are larger and double-ringed. This difference in shape and size and a subsequent difference in electrical charge is important, as it allows only specific complementary pairings between different group types; in DNA, adenine will only bond with thymine and cytosine will only bond with guanine. This creates nitrogenous base spindles of the same length and a mirror image on the opposite strand.
The double-helix form of DNA is caused by the shape of the monomer nucleotides. When asymmetrical molecules are stacked one on top of the other, a helix is often the result. In DNA, each strand runs antiparallel from the other, or in opposite directions.
The nucleotide monomer that makes up a single link of the DNA polymer chain is formed from a nucleobase, a phosphate group and a five-carbon (pentose) sugar called 2-deoxyribose. ‘Deoxy’ refers to the loss of an oxygen atom in relation to another form of pentose sugar known as ribose (see RNA). This lack of an oxygen atom also plays a role in the helical structure of DNA. The following image shows the difference in the chemical structure of these two pentose sugars. Note the absence of the red oxygen molecule on the second carbon of deoxyribose on the left.
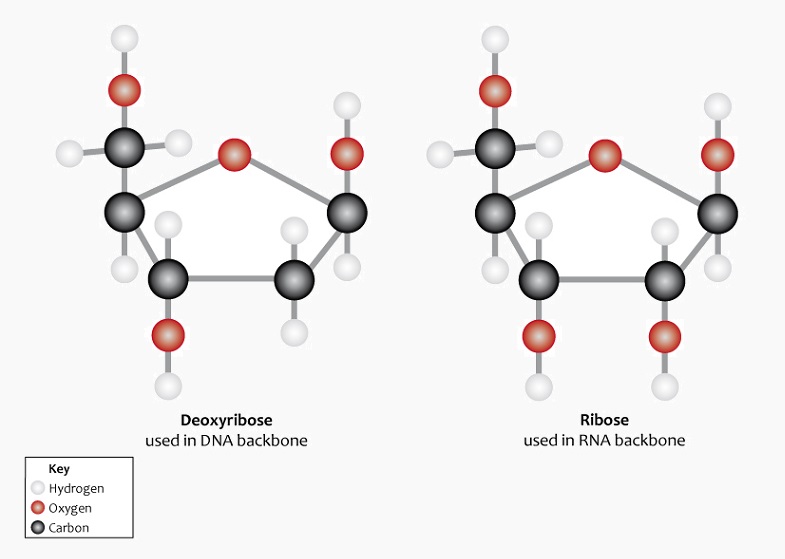
Deoxyribose bonds covalently with a phosphate group. This produces a chain known as the sugar-phosphate backbone. This structure leaves each nucleotide base open and free to bond with the correct nucleotide base on the opposite strand.
RNA
RNA is found in every type of cell. It is essential for the production of proteins via the replication of genetic information. Using the DNA blueprint, RNA in various forms copies and transfers encoded genetic data to cellular ribosomes. In turn, the ribosomes translate this data into the form of proteins. RNA is not associated with the double-helix structure of DNA. However, it has the ability to form this structure for a temporary period and exists in single strands of varying lengths. Even in denucleated red blood cells, RNA continues to carry out the process of transcription. This is because protein biosynthesis is necessary for every reaction within a living organism.
RNA Types
RNA has four main forms named according to its specific role. These are known as messenger RNA (mRNA), transfer RNA (tRNA), ribosomal RNA (rRNA) and non-coding RNA (ncRNA). Three of these – mRNA, tRNA, and rRNA – are responsible for the production of proteins from single amino acids according to the DNA blueprint. Non-coding RNA is a broad group of ribonucleic acids which do not produce proteins through DNA codes. Research into this group is still in its infancy, and many types are relegated to a category known as ‘junk’ RNA. However, large quantities of certain RNA types may indicate functions in areas such as chromosome structure, homeostasis, and cell physiology.
Nucleic Acid Structure of RNA
In relation to structure, RNA is very similar to DNA. The main differences are: the absence of a double-helix structure, ribose instead of deoxyribose, and uracil instead of thymine.
RNA is primarily found in single strands or folded forms. It tends to form a double-helix only on a temporary basis. The pentose sugar in the form of ribose that forms part of the sugar-phosphate backbone of RNA has an additional oxygen atom on the second carbon atom which forms a hydroxyl group. The nucleobase uracil – specific to RNA – replaces the thymine found in DNA. The image below clearly shows these structural and elemental differences.
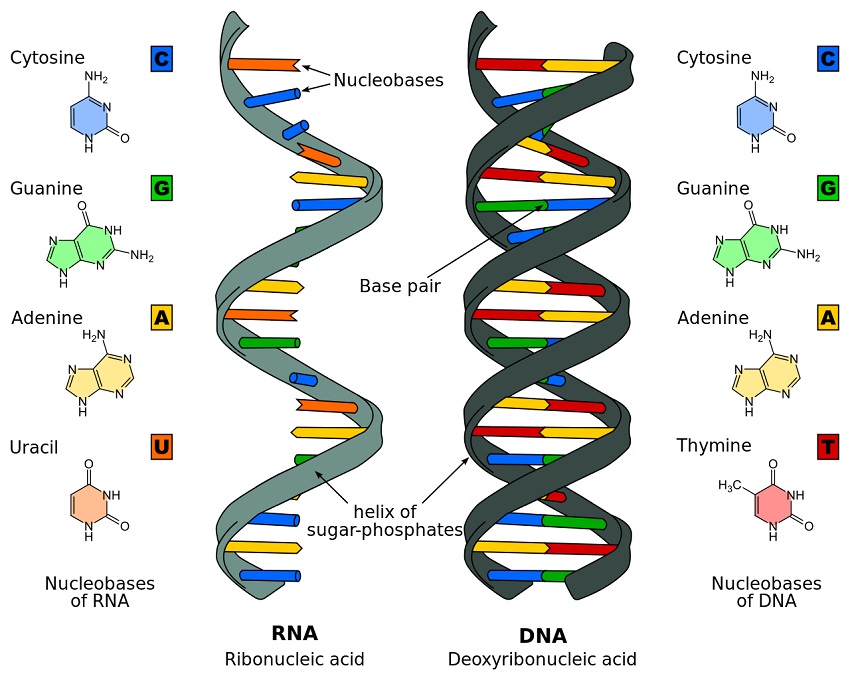
Nucleic Acid Structure
Nucleic acids can form huge polymers which can take on many shapes. As such, there are several ways to discuss nucleic acid structure. “Nucleic acid structure” can mean something as simple as the sequence of nucleotides in a piece of DNA. Or, it could mean something as complex as the way that DNA molecule folds and how it interacts with other molecules.
Here’s a little about each level of nucleic acid structure:
Primary Structure
Nucleotides – the building blocks of nucleic acids, and the “letters” of the genetic “code” – are made of two components:
- A nitrogenous base such as adenine, cytosine, guanine, and thymine or uracil. DNA and RNA each have four possible nitrogenous bases; where DNA uses thymine, or “T,” RNA uses uracil, or “U” instead of thymine.
Each of these four bases has different bonding properties, ensuring that the cell doesn’t “mix up” one letter with the other. Thymine and uracil have almost identical structures and properties, allowing them to fulfill similar roles in the two different types of nucleic acids. - A sugar-phosphate backbone, which allows the nitrogenous bases to be strung together. Each nucleotide’s sugar can link to another nucleotide’s phosphate to become a single molecule. When many nucleotides are strung together, the angle of this phosphate-sugar bond most often makes the string into a helix. This is why DNA, which is two-stranded, naturally takes on the shape of a double helix.
The primary structure of the nucleic acid refers to the sequence of its nucleotide bases, and the way these are covalently bonded to each other. The sequence of “letters” in a strand of DNA or RNA, then, is part of its primary structure, as is the helical or double-helical shape.
Secondary Structure
Secondary structure refers to how nucleotide bases hydrogen bond with each other, and what shape this creates out of their two strands.
The hydrogen bonds that form between complementary bases of two nucleic acid strands are quite different from the covalent bond that forms between sister monomers in a nucleic acid strand.
The bonds between bases in a single strand of nucleic acid are covalent – they fully share their electrons, and are bonded in a way that’s very difficult to break. Atoms linked by covalent bonds are all part of the same molecule.
Hydrogen bonds, on the other hand, are weak bonds that come from weak, temporary attractions between positively-charged hydrogen nuclei and the electrons of other atoms. The molecules don’t actually share electrons, so they can be separated fairly easily. Changes to environmental factors like acidity can also disrupt hydrogen bonds.
The most common secondary structure we’re familiar with is the double helix that forms when two complementary strands of DNA hydrogen bond with each other. Other structures are also possible, such as a “stem-loop” – which occurs when a single RNA molecule folds back and hydrogen bonds with itself – or a four-armed structure that can occur when four different strands of nucleic acid hydrogen bond with different parts of each other.
It is thought that some of these secondary structure possibilities are used to help control gene expression and perform other biological functions. In general, transcription enzymes will only express genes they can access. If a gene or RNA snippet is “tied up” in a tangle of nucleic acids, the enzymes may be less likely to reach it. Genes in more open, simple secondary structures, on the other hand, may be more likely to be expressed.
Tertiary Structure
Tertiary structure refers to the position of the atoms of a nucleic acid in space. There are several common measurements that are discussed when talking about the tertiary structure of a nucleic acid, including:
- “Handedness”
Asymmetrical molecules are very much like our hands. Each of our hands has the same shape, for example – the same components linked together in the same way. But our hands are clearly not interchangeable. That’s because one of our hands has the thumb on the right side, while the other has the thumb on the left. Rather than being identical, interchangeable structures, our hands are mirror images of each other.
In just the same way, asymmetrical molecules with the same parts and connectivity can be identical, or they can be mirror images of each other. Some molecules are “right-handed” while others are “left-handed” mirror images of these.
When it comes to biological molecules, “handedness” can be crucial to determining the effect that a chemical has on an organism. For some medicines and poisons, only one stereoisomer interacts with our body’s enzymes. One molecule may have no effect on us, while its mirror image may be beneficial or deadly. - Length of helix turn.
While any asymmetrical molecule can have a stereoisomer, as you might guess, “length of helix turn” is fairly unique to nucleic acids.
The angle of bonds between nucleotides causes most nucleic acids to form a helix shape. But small differences in the shape of the helix can cause differences in how the helix interacts with our enzymes and other molecules. So the details of this helix shape can be important! - Number of base pairs per turn.
This is another measure of the exact shape and properties of a nucleic acid helix. This can be chemically and biologically important, as it determines which enzymes and molecules can affect the DNA or RNA.
- Difference in size between major and minor grooves.
In a nucleic acid double helix, the “major groove” is the wider path that opens between two the two nucleic acid strands. The “minor groove” is the narrower one. In some cases, these grooves may serve as binding sites for other molecules.
The size of the major and minor grooves can vary depending on several factors, including the chemical environment of the double helix. Anything that affects the strength of hydrogen bonds can affect the size of the major and minor grooves.
Quaternary Structure
Quaternary structure refers to the large shapes and structures that can be made by nucleic acids. Much like the amino acids and proteins, nucleic acids can form large structures. The shape of these structures can be important to their functions.
Examples of nucleic acid quaternary structures include chromatids – huge molecules of DNA that are packed tightly for storage and transportation during cell division – and ribosomes, which are organelles made partially of RNA.
Some ribozymes also accomplish their jobs partially through the use of quaternary structure. This allows them to interact with their substrates. Just like enzymes made of protein, ribozymes must precisely fit their substrate in order to catalyze its chemical reactions.