Definition
Deoxyribonucleic acid, DNA, or desoxyribonucleic acid is a molecule with a double helix structure that carries the sequences of genetic code – the basis of all life. Packaged tightly into chromosomes, DNA can be copied and translated to manufacture specific proteins. It is self-regulating and primarily packed with non-protein forming sequences that have, as yet, to be fully understood. DNA replication occurs before cell division, passing on the entire organism’s genome to every daughter cell. During sexual reproduction, deoxyribonucleic acid merges to produce offspring that are a mix of both parents.

What is Deoxyribonucleic Acid?
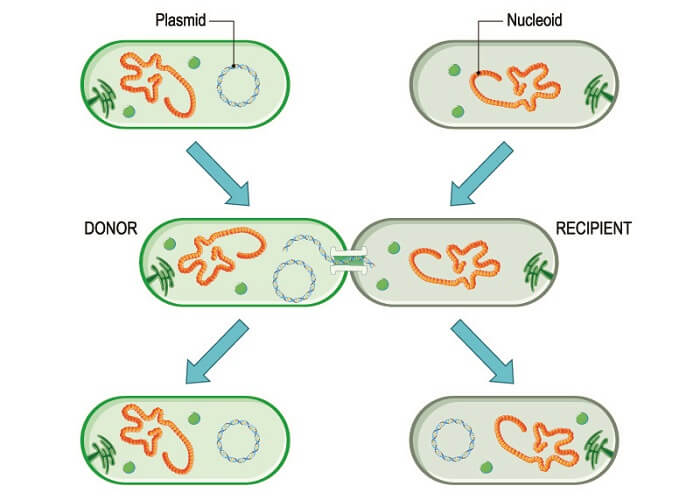
Deoxyribonucleic acid is one of two nucleic acids that store, carry and decode genetic information. DNA is found inside the cell nucleus of multicelled organisms, in the mitochondria, and as plasmids in the cytoplasm of some bacteria.
Deoxyribonucleic acid is also known as DNA. This macromolecule can be imagined as a recipe book containing the instructions that show how to build an organism from scratch. This book (genome) is ordered into chapters (chromosomes), pages (genes), sentences (alleles), and words (single nucleotides). It gives instructions about cooking times and seasonal dishes. Sometimes there are printing errors; sometimes part of a page becomes damaged. What is important to understand is that no cook can read this recipe book. It is not only locked shut, it is written in a strange language.
The other nucleic acid is ribonucleic acid (RNA) that plays the role of transcriber and translator. The DNA recipe book will only open a portion of a page when it is the right time to cook a specific dish; non-coding DNA is thought to tell the book when and where to open. The opened portion could show something as simple as a boiled egg or give instructions for a five-course meal. Wherever it opens, RNA makes a copy and brings it to the cook – the ribosome. Together, they translate the strange DNA language and mix the right ingredients.
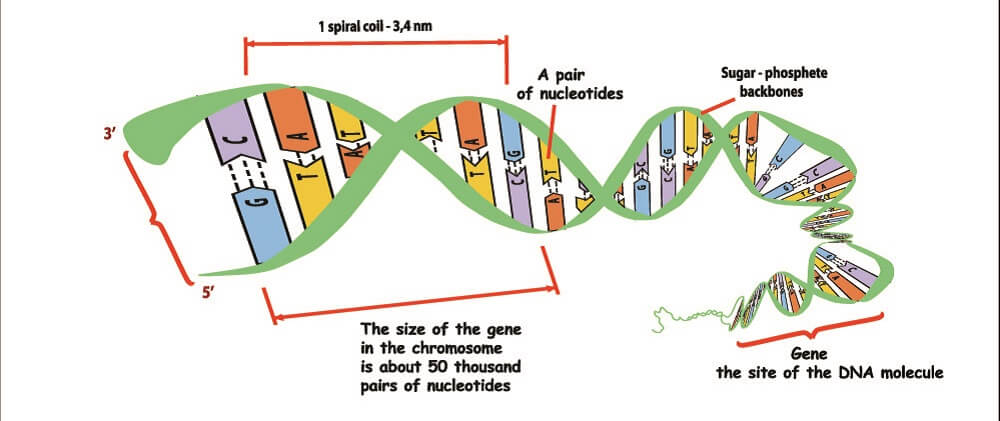
Deoxyribonucleic acid is a long chain of joined nucleotides (more about these later on). Two interlinked chains wrap around each other to form a double-helix. DNA is most commonly found as a tightly-packaged chromosome. Each chromosome set carries the entire history of the evolution of an organism – past and present. New scientific disciplines like molecular anthropology have been made possible through recent genetic breakthroughs.

Humans have 23 paired chromosomes that carry the code that is the human genome. Each pair is composed of mixed parent DNA; this ‘crossing over’ of genes between autosome pairs occurs much less in the two sex chromosomes (allosomes).
Components of DNA
To understand deoxyribonucleic acid structure one must first look at its individual components.
Nucleic acids are composed of chains of nucleotides – polynucleotides. DNA is a pair of wrapped polynucleotides. Each single nucleotide link is composed of a nucleoside and a phosphate group. The nucleoside can be further divided into nucleobase and pentose sugar. Four nucleobases are used: guanine, adenine, cytosine, and thymine.
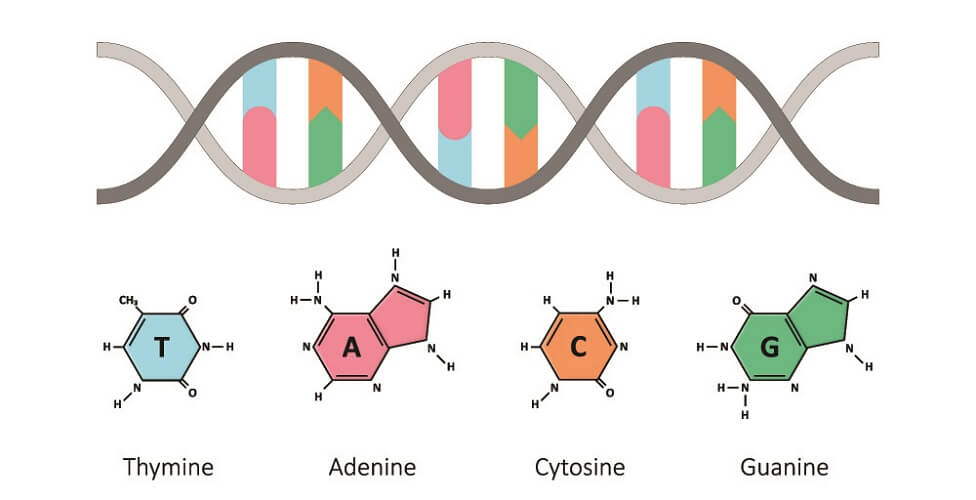
Within a piece of solid text, these statements can seem confusing. The components are more simply described as:
nucleobase + deoxyribose = nucleoside
nucleoside + phosphate = nucleotide
nucleotide chain = polynucleotide
2 polynucleotides = deoxyribonucleic acid (DNA)
Nucleobase
The four nucleobases are also referred to as bases or nitrogenous bases in many textbooks. Three of these are found in both DNA and RNA – adenine, cytosine, and guanine. The fourth is thymine in DNA (or uracil in RNA).
These DNA bases are split into two groups. This is important, as their binding ends provide the foundation of the language of the genetic code. Adenine and guanine – the purine bases – and cytosine and thymine – the pyrimidine bases – only bind to a base of the opposing group.
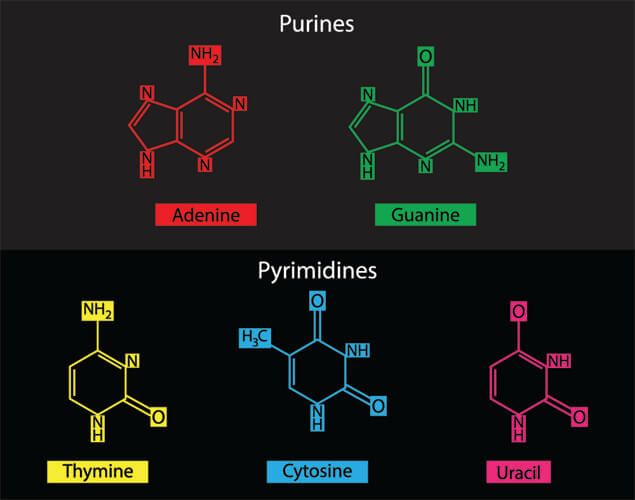
Furthermore, each base only binds to a specific partner – its base complement:
purine adenine to pyrimidine thymine
purine guanine to pyrimidine cytosine
and vice versa
Use AT the Cow Gate to remember these complement pairs.
As gene research continues, we now understand that DNA nucleobases can change form. If they degrade, they form different nucleobases that might or might not be confused with other bases. For example, when adenine degrades or loses its amine group it becomes hypoxanthine. Hypoxanthine is similar in form to guanine. During repairs, instead of attaching to thymine, the nucleobase bonds with cytosine. Depending on where this difference lies it has the potential to cause a malfunction in the actions of areas of non-coding DNA or during protein synthesis.
Deoxyribose
Deoxyribonucleic acid pronunciation can help us distinguish its characteristics. Deoxy tells us that the sugar (ribose) molecule contains less oxygen than in the compound it is derived from. Many of the most important mechanisms in living organisms, such as cellular respiration, depend on a good supply of ribose.
As the chemical formula for ribose is C5H10O5 and that of deoxyribose is C5H10O4, it is easy to see the difference. By removing one oxygen atom from ribose, place is made for the attachment of a nucleobase. As we have already seen, the combination of nucleobase and deoxyribose is a nucleoside. In the image below, we can see the difference in structure. Ribose is a component of ribonucleic acid or RNA, a critical component for protein synthesis.
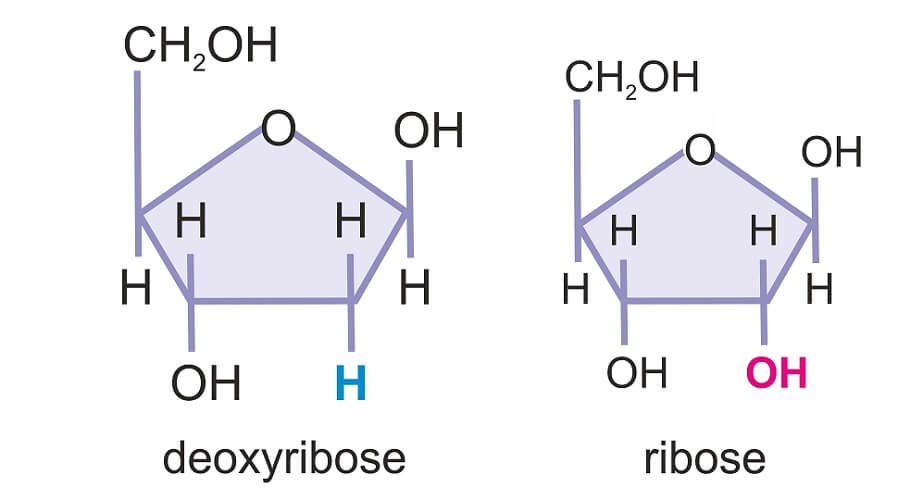
The deoxygenation of ribose to form deoxyribose for DNA production removes one oxygen atom. This occurs specifically at the second carbon atom where a hydroxyl group (OH) is attached; you might have seen the term 2-deoxyribose for this reason.
There are four deoxyribonucleosides (not including those found in degraded DNA): deoxyadenosine, deoxyguanosine, thymidine, and deoxycytidine.
Nucleotide and Polynucleotide
To produce a nucleotide from a nucleoside, just add phosphate. Nucleotides are composed of one nucleobase, one deoxyribose sugar, and one phosphate group.
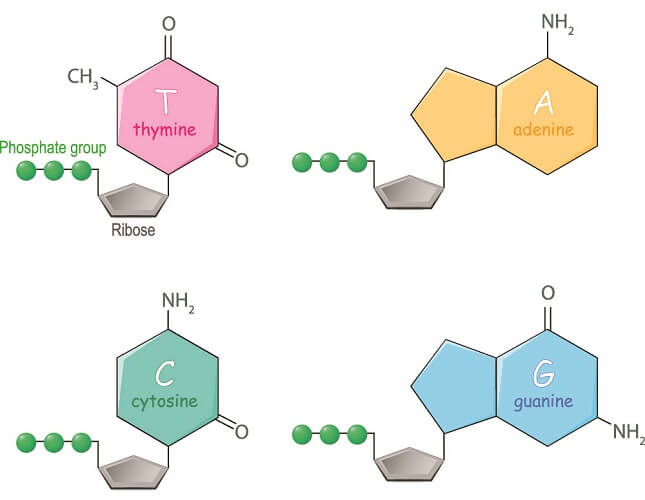
The phosphate group is often called the ‘DNA backbone’; however, it is also a source of energy in the form of deoxyadenosine triphosphate (dATP), deoxyguanosine triphosphate (dGTP), deoxycytidine triphosphate (dCTP), and deoxythymidine triphosphate (dTTP). When these lose two of their phosphate groups, they produce both nucleobases and energy for DNA replication.
Any chain of more than thirteen nucleotides is called a polynucleotide. As the human genome contains around three billion base pairs split into twenty-three chromosomes (six billion base pairs if we count all the nucleotides – expressed or not – from both parents), our DNA consists entirely of polynucleotides.
However, the number of base pairs has little to do with how complex an organism is. The garlic plant has more than double that of the human genome, and the longest bacterial (Chlorobium chlorochromatii) gene encodes for a 36 806 amino acid protein. To date, only one (human titin) coding sequence is longer.

Deoxyribonucleic Acid Structure
With a deeper knowledge of deoxyribonucleic acid terminology and components, it is easy to discuss DNA structure.
We have all seen images of the twisted ladder form of DNA. The DNA macromolecule is tightly wound into a right-handed double helix and packaged as a chromosome.
Deoxyribonucleic acid structure is composed of two nucleotide chain strands. Each strand runs anti-parallel to its partner. The double helix form not only saves space but is also highly protective. To protect the all-important nucleobases at the center, the backbone must wrap tightly around them; a single strand would not provide sufficient protection. A double-strand also allows DNA to correctly repair itself. If one side of a strand is damaged, only a new nucleobase that fits the opposite partner can be inserted. With each base having only one possible partner, this reduces the chance of mutation.
Imagine DNA as a ladder that is split down the middle to produce two symmetrical sides. The single rail of a single nucleotide chain is composed of deoxyribose and phosphate. The half-rungs of the ladder are individual nucleobases – A, T, C, and G. These two half-ladders make up a single DNA macromolecule. Opposite nucleobase pairs attach to provide the full rungs; sugar and phosphate rails twist tightly around them.
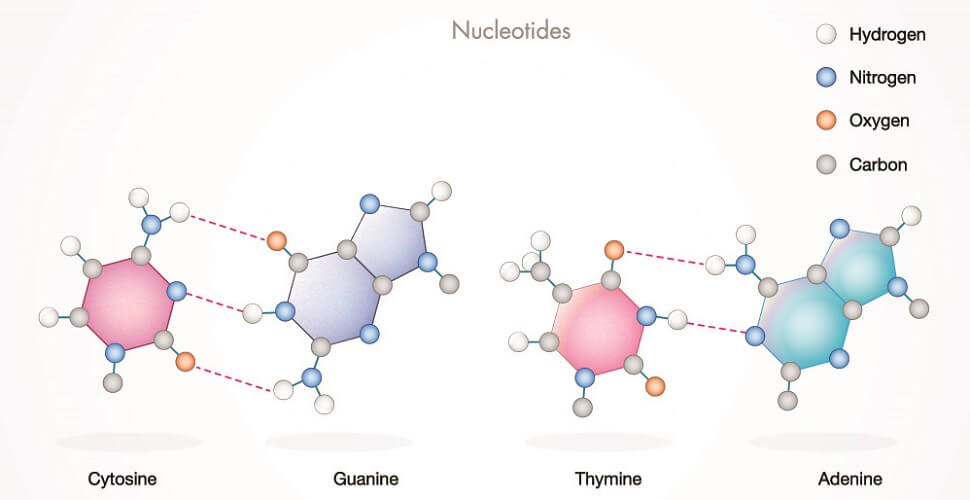
The bases connect by way of hydrogen bonds. Cytosine and guanine form three hydrogen bonds; adenine and thymine form two. Oxygen and nitrogen, found in all nitrogenous bases, are electronegative. Hydrogen atoms are positive. Adenine donates one of its hydrogens to the oxygen of thymine and one of its nitrogen atoms accepts a hydrogen atom from thymine. While such bonds are weak, the sheer numbers of base pairs provide a stable structure. These are not covalent bonds but the result of electromagnetic attraction. Guanine donates two hydrogen atoms to cytosine and accepts one.
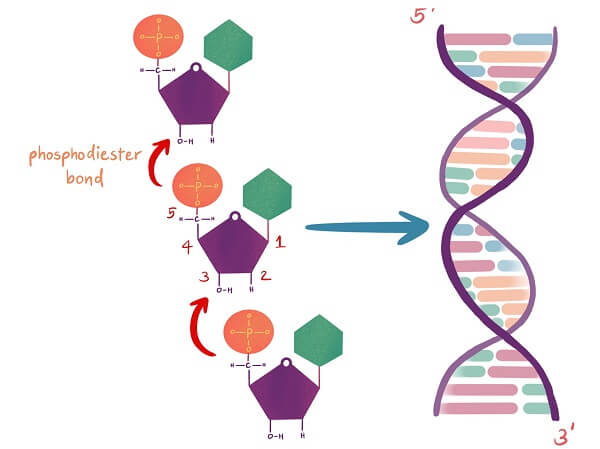
Nucleobases attach to deoxyribose to form nucleosides. This attachment is a glycosidic bond at the ninth nitrogen atom of a purine (adenine and guanine) or the first nitrogen atom of a pyrimidine (cytosine and thymine) to the second carbon of the deoxyribose molecule.
On the other side of the deoxyribose sugar ring, a phosphodiester bond holds the fourth carbon of that sugar to the methylene group (CH2) of a phosphate molecule.
Deoxyribonucleic Acid Function
Most of our knowledge of deoxyribonucleic function is attributed to coding DNA – the gene sequences that code for the production of proteins. Every living organism is composed of protein, fat, and carbohydrate; however, every organ and physiological system depends on proteins from the neurotransmitters of the brain to the soles of the feet.
Even so, only around two percent of the human genome codes for protein synthesis. Most DNA is non-coding. Some noncoding DNA plays a role in regulating gene activity, other parts organize DNA into chromosomes (satellite DNA) and regulate chromosome replication. Non-coding DNA is found within coding genes (introns) or outside the genes (intergenic DNA). While all used to be grouped under the term junk DNA, research is uncovering important roles.

We still know very little about the extent of non-coding deoxyribonucleic acid function. Non-coding DNA examples include:
- Pseudogenes: genes that once coded for proteins but have lost this function during evolution
- Repeat sequences: found at the ends of the chromosomes (telomeres) and protect against chromosome decay
- Operators: sequences that pause or halt gene expression.
Family Tree DNA
DNA ancestry research is becoming extremely accessible and attractive for those interested in genealogy. Both nuclear and mitochondrial DNA tests are used – mitochondrial DNA is only passed on from the maternal line. Ancient descendants are best detected through mitochondrial DNA as this form is most likely to remain intact.
All humans share the same DNA – or almost the same. The difference in DNA between you and a stranger only occurs in approximately one-tenth of a percent of the genome. Differences in single bases are called single nucleotide polymorphisms or ‘snips’. It is these snips that are grouped according to broad geographical locations or conditions and give individuals a very basic idea as to their roots.