Definition
The polypeptide definition describes a chain of more than twenty and less than fifty amino acids bound together via covalent peptide bonds. Singular amino acids are the building blocks of life and can be linked to form oligopeptides, polypeptides, and proteins inside the cell. This occurs during a process called protein synthesis. Varying sequences of the twenty-one essential and non-essential amino acids form a wide range of functional peptide-based molecules.
What is a Polypeptide?
To know what a polypeptide is, it is best to break it down into its smallest components – amino acids. Singular amino acid monomers link together to make more complex polymer chains.
Amino Acids
The twenty-one amino acids used to create and maintain life contain an amino group, a carboxyl group, an alpha carbon atom, a singular hydrogen atom, and a side chain (R group). The R group gives each amino acid its specific characteristics.
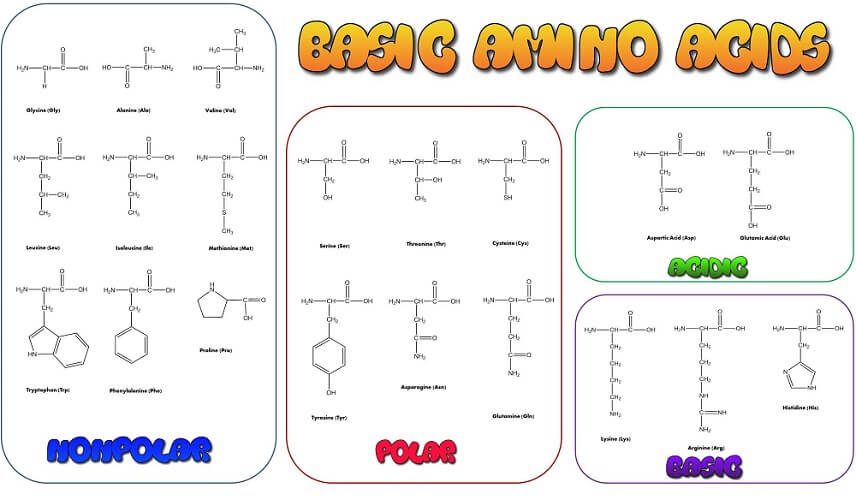
An amino group is comprised of one nitrogen and two hydrogen atoms. It is never found on its own because its valence shell has free electrons. It uses these free electrons to covalently bond with other molecules or elements – in the case of peptides it bonds to the central alpha carbon atom. Also attached to the carbon atom is a singular hydrogen atom and a carboxyl group.
A carboxyl group (COOH) is comprised of a carbon atom, a hydroxyl molecule (OH), and an oxygen atom. This oxygen atom has a double bond with the carboxyl carbon, making it a carbonyl (=O).

The R group is the distinguishing feature of individual amino acids. Sometimes called a side chain, the R group also bonds with the alpha carbon. While most textbooks refer to twenty human amino acids, a twenty-first – selenocysteine – exists in very low quantities. It is the result of a short gene sequence – a codon – that also encodes for the stop signals necessary during protein synthesis. Only recently have we discovered other uses for this highly volatile amino acid.
The R group of selenocysteine is CH2SeH. Other examples are glycine (C2H5NO2), serine (C3H7NO3), and tryptophan (C11H12N2O2). Glycine is the simplest amino acid with only one hydrogen atom as a side chain. It is, therefore, easiest to learn this amino acid structure by heart and so more easily remember the presence of the amino and carboxyl groups and the central carbon, and hydrogen atoms.
Polypeptide Synthesis
Polypeptide synthesis is a slightly confusing term as this process is also used in the manufacture of oligopeptides and proteins. While there is are differences between these molecules, their basic form – varying lengths of amino acid chains – is the same.
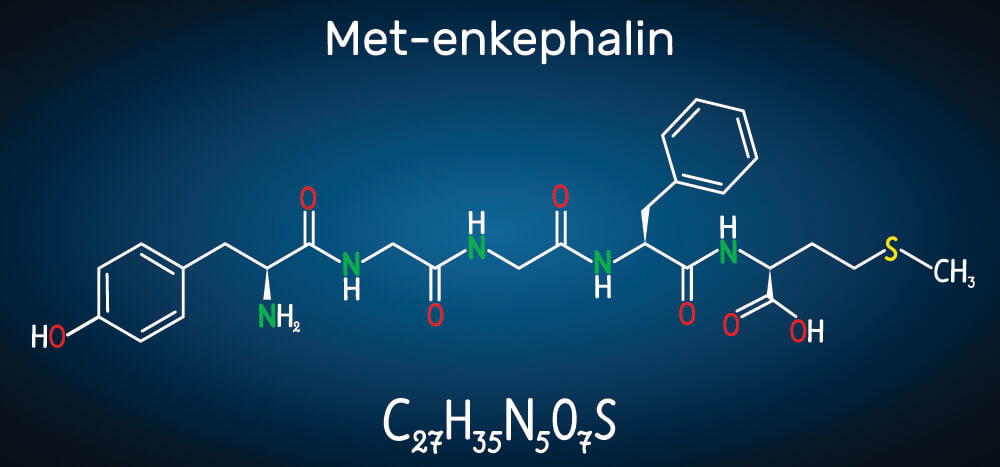
A singular amino acid is just that – an amino acid. The moment it bonds with another amino acid it becomes a peptide. No matter how many amino acids are linked together and no matter what the structure, joined amino acids are all peptides.
Peptides are further categorized according to length. Oligopeptides are linear chains of between two and twenty amino acids. A dipeptide – the result of two bonded amino acids – is also an oligopeptide, as is a pentapeptide (five bonded amino acids) as depicted in the above image.
Linear chains of between twenty and fifty amino acids are called polypeptides. These can form primary or secondary structures.
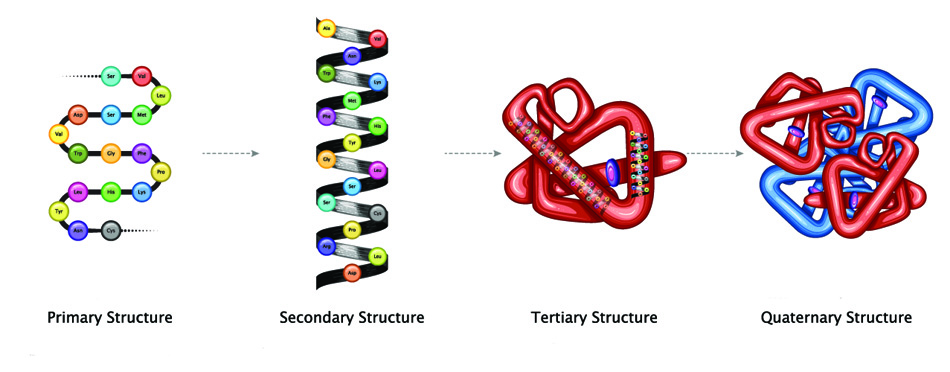
Larger peptides are categorized according to their structure. Proteins contain at least fifty amino acids and often wrap into distinct shapes. They are grouped into primary, secondary, tertiary, and quaternary structures. For a more complex protein to be constructed, it must first exist in the preceding form.
- Primary structure refers to the amino acid order of a simple peptide chain.
- Secondary structures – commonly alpha-helix, beta-strand, or beta-sheet – create spirals, coils, or sheet forms from a single polypeptide chain by way of hydrogen bonds.
- Tertiary structure also concerns a single polypeptide chain but further folds the secondary structure to make a globule-like molecule held in place by hydrogen bonds and salt bridges, for example.
- Quaternary structures involve two or more polypeptide chains that join to produce a protein with a single function. Hemoglobin, the oxygen-carrying molecule in our blood – is a quaternary protein made of two pairs of bound polypeptide chains.
Encoded information that produces any peptide is found inside the DNA of the cell nucleus. When required, this information is copied directly from a DNA template strand to form a transcribed strand of messenger RNA. Messenger RNA (mRNA), as its name suggests, carries this encoded information outside the cell nucleus and toward a ribosome.
Ribosomes distinguish ordered groups of three nucleic acids (codons) within the mRNA strand and match these codons to singular amino acids attached to transport RNA (tRNA). Within the ribosome, these amino acids are linked together in the order dictated by the strand of mRNA by way of peptide bonds.
Peptide Bonds
A ribosome links two amino acids by way of peptide bonds. These are covalent chemical bonds between the carboxyl group of one amino acid and the amino group of the other. When these two residues attach, they release a single molecule of water – a dehydration synthesis reaction. The carboxyl group loses its negatively-charged hydroxyl ion and the amino group loses a positively-charged hydrogen ion to form H20. The linked amino acids dehydrate and water is produced, so this process is also described as a condensation reaction. This loss of ions from the newly-linked amino acid molecules explains why many textbooks say polypeptides and proteins are constructed from amino acid residues.
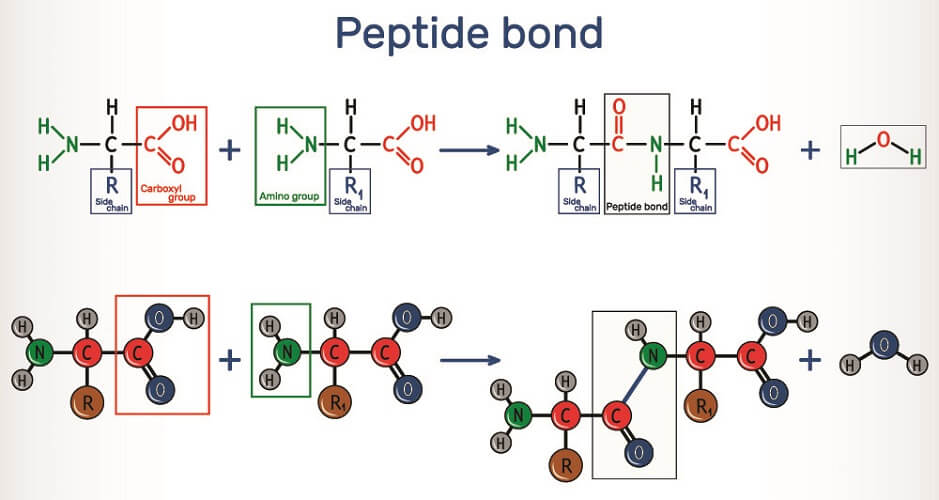
To form a peptide bond, the ribosome helps to push the carboxyl group of one amino acid closer to the amino group of the next. The formation of a peptide bond requires energy in the form of adenosine triphosphate (ATP).
It is possible to reverse this reaction by adding water; however, breaking a peptide bond this way occurs at a much slower rate than the dehydration synthesis reaction. This is because amino acid residues have an extra double bond. In the body, enzymes speed up this reaction.
When water is added, its -OH ion degrades the positive charge of the carboxyl’s carbon atom and this bond loosens. The +H ion of the water molecule affects the negative nitrogen ion of the amino group. Both actions break apart the peptide bond and reinstate complete carboxyl and amino groups in both amino acids. For the polypeptide bond, the number of amino acids in a chain should number twenty to fifty and the corresponding number of bonds between nineteen and forty-nine.
Polypeptide Structure
Polypeptide structure is simple in comparison to protein structure. Each chain has two terminal ends:
- N-terminal: free amino group end of the polypeptide chain.
- C-terminal: free carboxyl group end of the polypeptide chain.
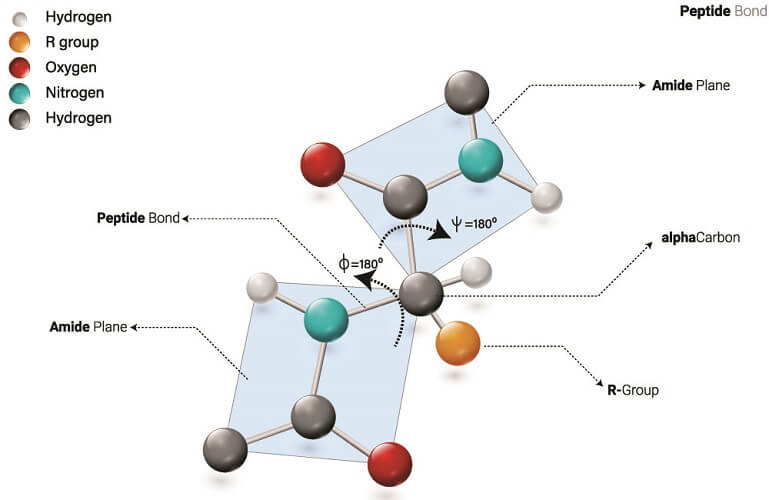
Polypeptide structure can be the same as the primary or secondary structures of proteins but has fewer amino acids per chain. The number of amino acids they contain means they are not officially referred to as proteins but as polypeptides.
Shorter polypeptide chains do not form more complex structures. The length of the amino acid chain and the structure in which these chains exist are protein and polypeptide distinguishing features. However, in principle, all proteins are polypeptides.
Polypeptide Examples
Polypeptide examples are found in nature and can be manufactured as synthetic chemicals. They exist in every living organism, from bacteria to blue whales.

A polypeptide example is a component of snake venom called natriuretic peptide. The human body also produces less potent forms of this peptide, as do other mammals, reptiles, plants, fish, and bacteria.
One of the deadliest snake venoms contains Dendroaspis natriuretic peptide (DNP). DNP is a polypeptide chain of thirty-eight amino acids. A green mamba snake bite containing DNP inhibits angiotensin-converting enzyme – part of the system that relaxes the arteries. This mechanism allows the poison to better circulate throughout the body. Pharmaceutical companies use this natural polypeptide in ACE-inhibitor drugs that are extremely useful in the treatment of chronic hypertension.

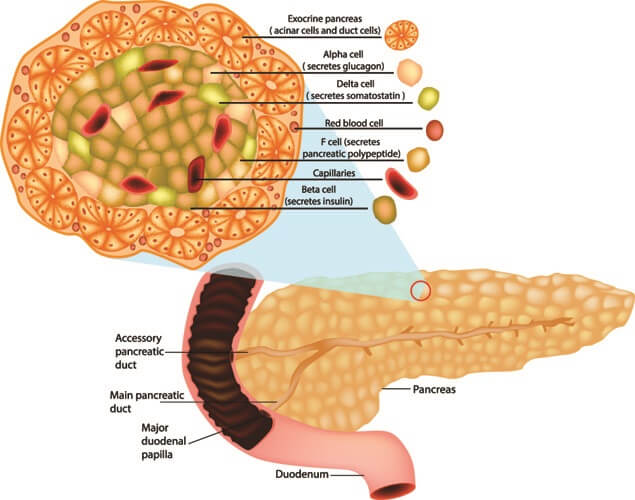
Glucagon is a single-chain polypeptide with twenty-nine amino acid residues and is manufactured by alpha cells in the pancreas. These cells express the gene that encodes glucagon synthesis. Glucagon is a hormone excreted into the bloodstream when blood sugar levels are low. The hormone arrives at the liver and its presence tells the liver to convert glycogen into glucose.
Pancreatic polypeptide produced in F cells in the Islets of Langerhans regulates the secretion of other pancreatic hormones such as glucagon. This chain of thirty-six amino acids also aids digestion.
Polypeptide antibiotics are produced by many types of bacteria. These natural polypeptides protect single-celled organisms from toxins released by other bacteria species. The huge increase in antibiotic resistance in human and livestock populations is raising alarm bells concerning the future of current antibiotic therapies; alternative drugs are always of interest. The antibiotic from one bacteria type could lower the rate of proliferation of other, more harmful types. Even so, current polypeptide antibiotics are associated with a wide range of allergic symptoms including rash, nausea, and breathing problems.
A synthetic polypeptide example covers the chemicals produced to research, design, and prepare novel enzymes, drugs, and vaccines. As peptide synthesis in smaller laboratories is a time-consuming task, industrial-sized companies produce specific peptides on a massive scale. The first peptides to be synthesized were the hormones oxytocin and insulin. Current technology allows companies to produce less reactive polypeptides that provide lower levels of undesired reactions with other molecules. This is done through the addition of temporary or permanent protecting chemicals (benzyl or tert-butyl groups) during synthetic polypeptide synthesis.
Medical artificial bio-active noninsulin polypeptides are few in number – around thirty have been approved for global use; however, nearly two hundred are currently undergoing trials.
Beauty products such as protini polypeptide cream contain synthetic polypeptide chains such as sh-Polypeptide-1, sh-Polypeptide-9, and sh-Polypeptide-11. These are biomimetic synthetic human (sh) polypeptides made to copy the actions of those growth factors that produce anti-aging effects in the skin.

On the other end of the scale, our growing catalog of efficient cancer therapies includes peptide-based chemotherapies in the form of peptide vaccines and peptide-nanoparticle conjugates. Conjugates are transportation molecules designed to bring anticancer agents directly to cancer cells, increase the efficiency of medical imaging, and influence tumor growth rates.