Genetic Code Definition
The genetic code is the code our body uses to convert the instructions contained in our DNA the essential materials of life. It is typically discussed using the “codons” found in mRNA, as mRNA is the messenger that carries information from the DNA to the site of protein synthesis.
Everything in our cells is ultimately built based on the genetic code. Our hereditary information – that is, the information that’s passed down from parent to child – is stored in the form of DNA. That DNA is then used to build RNA, proteins, and ultimately cells, tissues, and organs.
Like binary code, DNA uses a chemical language with just a few letters to store information in a very efficient manner. While binary uses only ones and zeroes, DNA has four letters – the four nucleotides Adenine, Cytosine, Guanine, and Thymine/Uracil.
Thymine and Uracil are very similar to each other, except that “Thymine” is slightly more stable and is used in DNA. Uracil is used in RNA, and has all the same properties of Thymine except that it is slightly more prone to mutate.
This doesn’t matter in RNA, since new RNA copies can be produced from DNA at any time, and most RNA molecules are intentionally destroyed by the cell a short time after they’re produced so that the cell does not waste resources producing unneeded proteins from old RNA molecules.
Together, these four letters of A, C, G, and T/U are used to “spell” coded instructions for each amino acid, as well as other instructions like “start transcription” and “stop transcription.”
Instructions for “start,” “stop,” or for a given amino acid are “read” by the cell in three-letter blocks called “codons.” When we talk about “codons,” we usually mean codons in mRNA – the “messenger RNA” that is made by copying the information in DNA.
For that reason, we talk about codons made of RNA, which uses Uracil, instead of the original DNA code which uses Thymine.
Each amino acid is represented in our genetic instructions by one or more codons, as seen below.
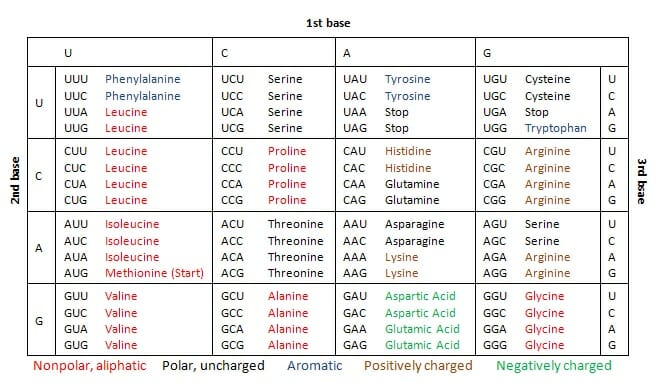
One of the most remarkable evidences for the common descent of all life on Earth from a single ancestor is the fact that all organisms use the same genetic code to translate DNA into amino acids.
There are a few slight exceptions to be found, but the genetic code is similar enough across organisms that when a gene from a plant or jellyfish is injected into a mammal cell, for example, the mammal cell will read the gene in the same way and build the same product as the original plant or jellyfish!
Function of Genetic Code
The genetic code allows cells to contain a mind-boggling amount of information.
Consider this: a microscopic fertilized egg cell, following the instructions contained in its genetic code, can produce a human or elephant which even has similar personality and behaviors to those of its parents. There is a lot of information in there!
The development of the genetic code was vital because it allowed living things to reliably produce products necessary for their survival – and pass instructions for how to do the same onto the next generation.
When a cell seeks to reproduce, one of the first things it does is make a copy of its DNA. This is the “S” phase of the cell cycle, which stands for the “Synthesis” of a new copy of the cell’s DNA.
The information encoded in DNA is preserved by the specific pairing of DNA bases with each other. Adenine will only bond with Thymine, Cytosine with Guanine, etc..
That means that when a cell wants to copy its DNA, all it has to do is part the two strands of the double helix and line up the nucleotides that the bases of the existing DNA “want” to pair with.
This specific base pairing ensures that the new partner strand will contain the same sequence of base pairs – the same “code” – as the old partner strand. Each resulting double helix contains one strand of old DNA paired with one strand of new DNA.
These new double helixes will be inherited by two daughter cells. When it’s time for those daughter cells to reproduce, each strand of these new double helices, act as templates for a new double helix!
When the time comes for a cell to “read” the instructions contained within its DNA, it uses the same principle of specific pair bonding. RNA is very similar to DNA, and each RNA base bonds specifically to one DNA base. Uracil binds to Adenine, Cytosine to Guanine, etc..
This means that, just like DNA replication, the information in DNA is accurately transferred to RNA as long as the resulting RNA strand is composed of the bases that bind specifically with the bases in the DNA.
Sometimes, the RNA strand itself can be the end product. Structures made of RNA perform important functions in ourselves, including assembling proteins, regulating gene expression, and catalyzing the formation of proteins.
In fact, some scientists think that the first life on Earth might have been composed mainly of RNA. This is because RNA can store information in its base pairs just like DNA, but can also perform some enzymatic and regulatory functions.
In most cases, however, the RNA goes on to be transcribed into a protein. Using the amino acid “building blocks of life,” our cells can build almost protein machines for almost any purpose, from muscle fibers to neurotransmitters to digestive enzymes.
In protein transcription, the RNA codons that were transcribed from the DNA are “read” by a ribosome. The ribosome finds the appropriate transfer RNA (tRNA) with “anti-codons” that are complimentary to the codons in the messenger RNA (mRNA) that has been transcribed from the DNA.
Ribosomes catalyze the formation of peptide bonds between the amino acids as they “read” each codon in the mRNA. At the end of the process, you have a string of amino acids as specified by the DNA – that is, a protein.
Other building blocks of life, such as sugars and lipids, are in turn created by proteins. In this way the information contained in the DNA is transformed into all of the materials of life, using the genetic code!
Types of Genetic Mutations
Because the genetic code contains the information to make the stuff of life, errors in an organism’s DNA can have catastrophic consequences. Errors can happen during DNA replication if the wrong base pair is added to a DNA strand, if a base is skipped, or if an extra base is added.
Rarely, these errors may actually be helpful – the “mistaken” version of the DNA may work better than the original, or have an entirely new function! In that case, the new version may become more successful, and its carrier may outcompete carriers of the old version in the population. This spread of new traits throughout a population is how evolution progresses.
Silent Mutations and Redundant Coding
In some cases, genetic mutations may not have any effect at all on the end product of a protein. This is because, as seen in the table above, most amino acids are connected to more than one codon.
Glycine, for example, is coded for by the codons GGA, GGC, GGG, and GGU. A mutation resulting in the wrong nucleotide being used for the last letter of the glycine codon, then, would make no difference. A codon starting in “GG” would still code for glycine, no matter what letter was used last.
The use of multiple codons for the same amino acid is thought to be a mechanism evolved over time to minimize the chance of a small mutation causing problems for an organism.
Missense Mutation
In a missense mutation, the substitution of one base pair for an incorrect base pair during DNA replication results in the wrong amino acid being used in a protein.
This may have a small affect on an organism, or a large one – depending on how important the amino acid is to the function of its protein, and what protein is effected.
This can be thought of like furniture construction. How bad would it be if you used the wrong piece to bolt a chair leg in place? If you used a screw instead of a nail, the two are probably similar enough that the chair leg would stay on – but if you tried to use, say, a seat cushion to connect the leg to the chair, your chair wouldn’t work very well!
A missense mutation may result in an enzyme that almost as well as the normal version – or an enzyme that does not function at all.
Nonsense mutation
A nonsense mutation occurs when the incorrect base pair is used during DNA replication – but where the resulting codon does not code for an incorrect amino acid.
Instead, this error creates a stop codon or another piece of information that is indecipherable to the cell. As a result, the ribosome stops working on that protein and all subsequent codons are not transcribed!
Nonsense mutations lead to incomplete proteins, which may function very poorly or not at all. Imagine if you stopped assembling a chair halfway through!
Deletion
In a deletion mutation, one or more DNA bases are not copied during DNA replication. Deletion mutations come in a huge range of sizes – a single base pair may be missing, or a large piece of a chromosome may be missing!
Smaller mutations are not always less harmful. The loss of just one or two bases can result in a frameshift mutation that impairs a crucial gene, as discussed under “frameshift mutations” below.
By contrast, larger deletion mutations may be fatal – or may only result in disability, as in DiGeorge Syndrome and other conditions that result from the deletion of part of a chromosome.
The reason for this is that DNA is very much like computer source code – one piece of code might be crucial for the system to turn on at all, while other pieces of code might just ensure that a website looks pretty or loads quickly.
Depending on the function of the piece of code that is deleted or otherwise mutated, a small change can have catastrophic consequences – or a seemingly large corruption of code one can result in a system that is just a bit glitchy.
Insertion
An insertion mutation occurs when one or more nucleotides is erroneously added to a growing DNA strand during DNA replication. On rare occasions, long stretches of DNA may be incorrectly added in the middle of a gene.
Like a missense mutation, the impact of this can vary. The addition of an unnecessary amino acid in a protein may make the protein only slightly less efficient; or it may cripple it.
Consider what would happen to your chair if you added a random piece of wood to it that the instructions did not call for. The results could vary a lot depending on the size, shape, and placement of the extra piece!
Duplication
A duplication mutation occurs when a segment of DNA is accidentally replicated two or more times. Like the other mutations listed above, these may have mild effects – or they may be catastrophic.
To imagine if your chair had two backs, two seats, or eight legs. A small duplication and the chair may still be useable, if a little odd-looking or uncomfortable. But if the chair had, for example, six seats attached to each other, it may rapidly become useless for its intended purpose!
Frameshift mutation
A frameshift mutation is a subtype of insertion, deletion, and duplication mutations. In a frameshift mutation, one or two amino acids are deleted or inserted – resulting in a shifting of the “frame” which the ribosome uses to tell where one codon stops and the next begins.
This type of error can be especially dangerous because it causes all codons that occur after the error to be misread. Typically, every amino acid added to the protein after the frameshift mutation is wrong.
Imagine if you were reading a book – but at some point during the writing, a programming error happened such that every subsequent letter shifted one letter later in the alphabet.
A word that was supposed to read “letter” would suddenly become “mfuuft.” Boe tp po.
This is approximately what happens in a frameshift mutation.
Quiz
1. The base pairing rules of DNA and RNA are as follows:
- A – T/U (Uracil is used instead of thymine in RNA.)
- C – G
- G – C
- T/U – A
Given that, which of the following would be the anti-codon sequence for an mRNA codon reading “UUGCUGCAG?”
A. AAGGACGUC
B. AACGAGGUC
C. AACGACGUC
D. AACGACGUG
2. Which of the following could NOT occur as a result of the deletion of a single nucleotide?
A. A missense error.
B. A nonsense error.
C. A frameshift mutation.
D. None of the above.
3. What amino acid string is coded for by the mRNA sequence UUGCUGCAG?
A. Leucine-Isoleucine-Glutamine
B. Leucine-Leucine-Glutamine
C. Leucine-Leucine-Arginine
D. Isoleucine-Isoleucine-Glutamine
References
- What kinds of gene mutations are possible? – Genetics Home Reference. (n.d.). Retrieved May 10, 2017, from https://ghr.nlm.nih.gov/primer/mutationsanddisorders/possiblemutations
- Writer, L. G. (2016, September 29). Do Humans and Bacteria Share Common Genetic Codes? Retrieved May 10, 2017, from http://education.seattlepi.com/humans-bacteria-share-common-genetic-codes-4511.html
- Crick, F. (1990). What mad pursuit: a personal view of scientific discovery. Harmondsworth: Penguin.