AP Biology 6.1 - DNA and RNA Structure
This section of the AP Biology curriculum takes a deeper look at DNA and RNA structure in different organisms. We’ll start by reviewing the basics of nucleic acids (which was covered in more detail in section 1.6). Then, we’ll see how DNA and RNA structure is like protein structure in that it can be broken down into primary, secondary, tertiary, and quaternary structures. We’ll see some of the specific roles these different structures play in cells (such as tRNAs and ribozymes). Then, we’ll take a look at the structural and functional differences between circular and linear chromosomes. Finally, we’ll see how prokaryotic organisms can use tiny circular DNA molecules called plasmids to transfer important genes between cells.
Video Tutorial
The following video summarizes the most important aspects of this topic!
To watch more tutorial videos like this, please click here to see our full Youtube Channel!
Resources for this Standard
For Students & Teachers
- Overview & Video Tutorial (This article)
- Quick Test Prep
- Crossword Puzzle
For Teachers Only
ENDURING UNDERSTANDING
IST-1
Heritable information provides for continuity of life.
LEARNING OBJECTIVE
IST-1.K
Describe the structures involved in passing hereditary information from one generation to the next.
IST-1.L
Describe the characteristics of DNA that allow it to be used as the hereditary material.
ESSENTIAL KNOWLEDGE
IST-1.K.1
DNA, and in some cases RNA, is the primary source of heritable information.
IST-1.K.2
Genetic information is transmitted from one generation to the next through DNA or RNA–
- Genetic information is stored in and passed to subsequent generations through DNA molecules and, in some cases, RNA molecules.
- Prokaryotic organisms typically have circular chromosomes, while eukaryotic organisms typically have multiple linear chromosomes.
IST-1.K.3
Prokaryotes and eukaryotes can contain plasmids, which are small extra-chromosomal, double-stranded, circular DNA molecules.
IST-1.L.1
DNA, and sometimes RNA, exhibits specific nucleotide base pairing that is conserved through evolution: adenine pairs with thymine or uracil (A-T or A-U) and cytosine pairs with guanine (C-G)–
- Purines (G and A) have a double ring structure.
- Pyrimidines (C, T, and U) have a single ring structure.
6.1 DNA and RNA Structure Overview
All life on Earth, from the single-celled bacterial cells that populate every inch of the globe, to the multicellular fungi that serve as nutrient recyclers in various ecosystems, to plants big and small, to animals of all sizes, use the same basic DNA and RNA molecules to store and transmit genetic information.
The differences between DNA and RNA are minute, but understanding their structure is an important foundation to understanding the molecular basis of genetics. While prokaryotes and eukaryotes use essentially the same molecules to store genes, there are important structural differences and methods that these organisms use to transmit genetic information. This information will definitely be on the AP Test. So, follow along as we cover everything you need to know about DNA and RNA structure!
Before we dive into the specific structures of DNA and RNA, let’s take a look at the general purposes of these structures and the reasons they exist. This will be an extremely short review since we covered most of these topics in detail in our video on section 1.6.
DNA exists as a double-helix, with two strands held together by hydrogen bonds between nitrogenous bases. By contrast, RNA exists as a single strand. There are several functional reasons for this difference. DNA stores genetic information for long periods of time and a double-stranded structure can help it protect the information from damage. The double-stranded structure also helps it detect when damage has taken place since the base pairing between strands will become disrupted.
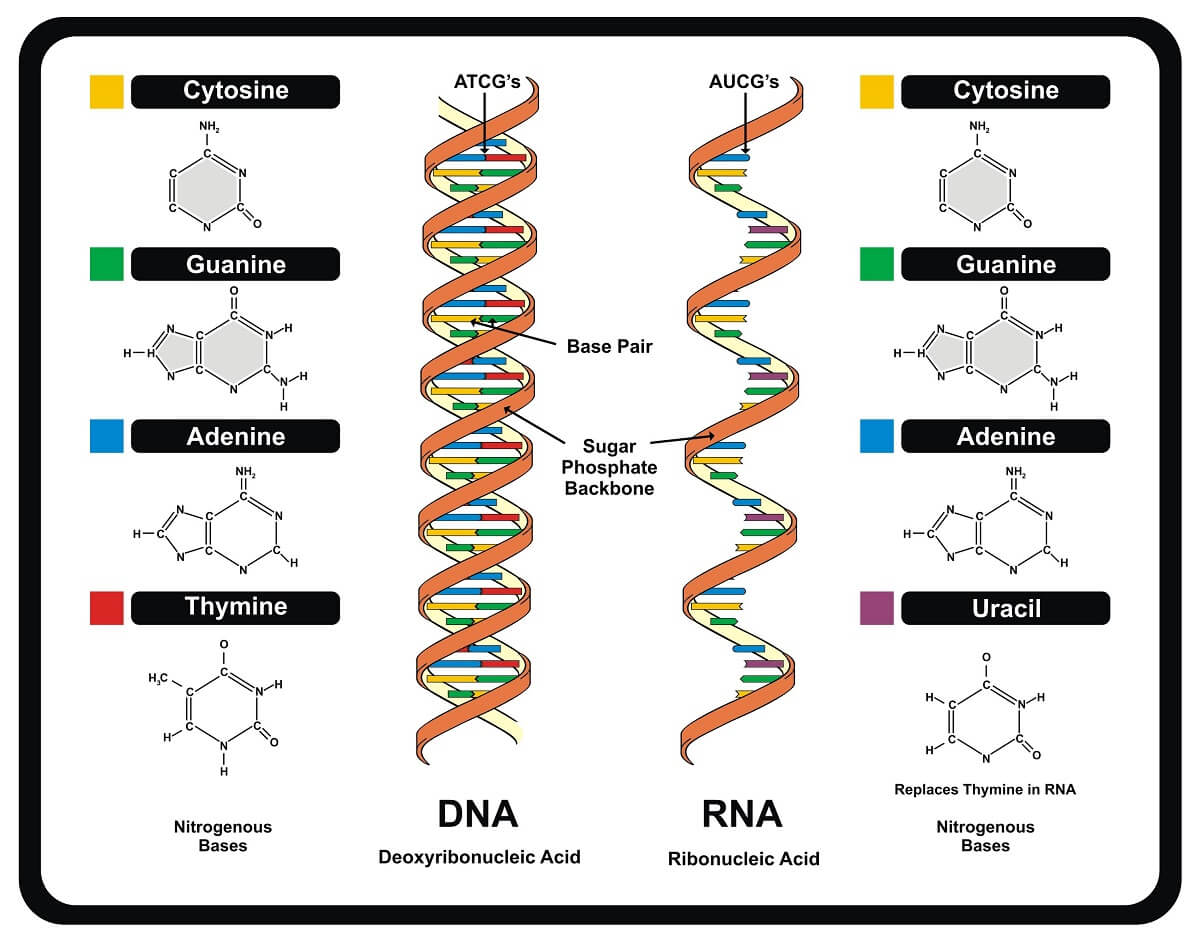
RNA, on the other hand, exists only for a short period of time in most organisms and is not typically the primary source of heritable information. RNA is simply transcribed from the DNA and can easily exit the nucleus as a single strand to be translated into a protein. Some viruses break this rule, using RNA as a primary storage molecule for their genetic code.
Between DNA and RNA, there are only a few structural differences at the molecular level. As their names imply, ribonucleic acid uses ribose in the sugar-phosphate backbone, while deoxyribonucleic acid uses deoxyribose. While the only difference between these two sugar molecules is the presence of a single oxygen atom, this makes a structural and functional difference. The oxygen in ribose makes this section of the sugar much larger and makes this section more electronegative. This tends to make RNA more reactive than DNA, part of the reason it is shorter-lived. This not only changes the specific structure of the sugar-phosphate backbone but also makes it harder for RNA to form a double-helix structure unless the perfect base pairs are created (such as in tRNA molecules).
The only other difference between DNA and RNA is the exact nucleotide monomers they use to create a strand. While these are mostly the same, DNA uses thymine while RNA uses uracil. This difference helps the cell recognize the difference between DNA and RNA, and uracil is slightly less energetically expensive to produce, saving the cell some energy.
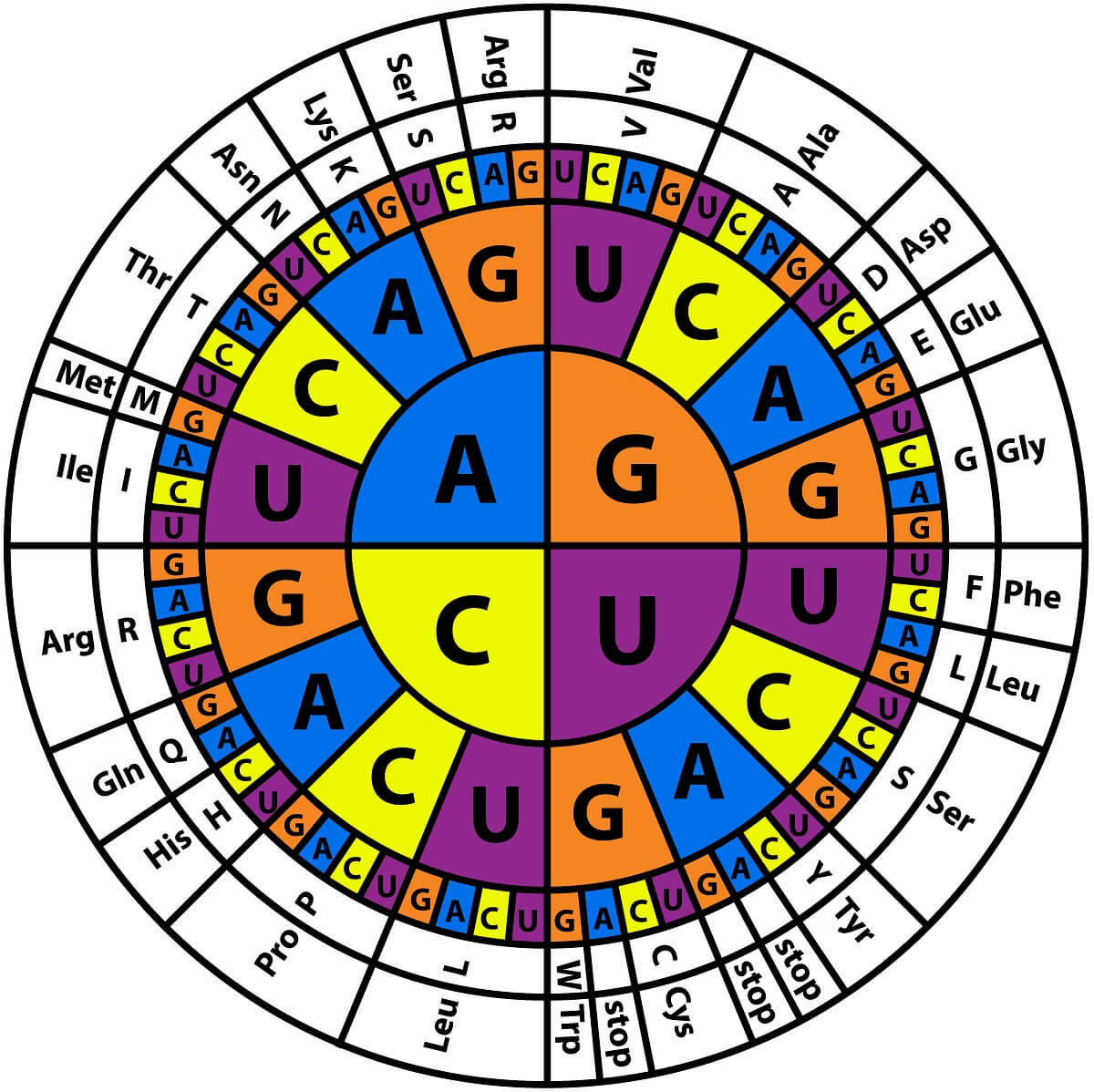
Before we take a closer look at DNA and RNA structure, let’s take a look at how these molecules actually store genetic information. Information is stored in DNA and RNA in the sequence of nucleotides within each molecule. This sequence is copied during RNA transcription, creating an RNA molecule that carries the same information. This RNA molecule leaves the nucleus, and it is translated into a protein by a ribosome. Within the ribosome, sets of 3 nucleotides called codons are matched to anticodons on tRNA molecules.
Each tRNA has a specialized anticodon and carries a specific amino acid. One reason we assume that all life on Earth comes from a common ancestor is that all organisms use the same basic code to tell ribosomes how to construct proteins. This codon is “read” in sequence from the 1st nucleotide, to the second, to the third, to determine what amino acid is added to the growing polypeptide chain. For example, a codon of GAA signals to the ribosome that it should add glutamic acid to the growing polypeptide chain – in all organisms!
Like proteins, DNA and RNA have a primary, secondary, tertiary, and even quaternary structure. Primary structure is made from the specific sequence of nucleotides. Secondary structure is formed mostly by base-pairing, making a helix between two strands or a stem-loop when one strand folds back on itself. The tertiary structure of both DNA and RNA is formed both by base pairing and the unique interactions between different nucleotides and the sugar-phosphate backbone. Quaternary structure is formed when DNA or RNA molecules form larger complexes with other nucleic acids or proteins.
Since many of these structures are formed by the process of base-pairing, let’s take a closer look at how this works. If you remember how hydrogen bonds work from Unit 1, you remember that hydrogen bonds are formed between the positive and negative charges held on two polar molecules. The purines (with a double-ring structure) form hydrogen bonds with a specific pyrimidine (with a single-ring structure). Since each nucleotide base has a specific charge, it can only bind with its complementary nucleotide base. So, G always binds with C, while A always binds with T (or Uracil in the case of RNA). If the bases approach each other in any other combination, similar charges repel each other. Therefore, correct base pairing is necessary for the normal double-helix structure of DNA and the several different forms of folded RNA (such as tRNA and rRNA).
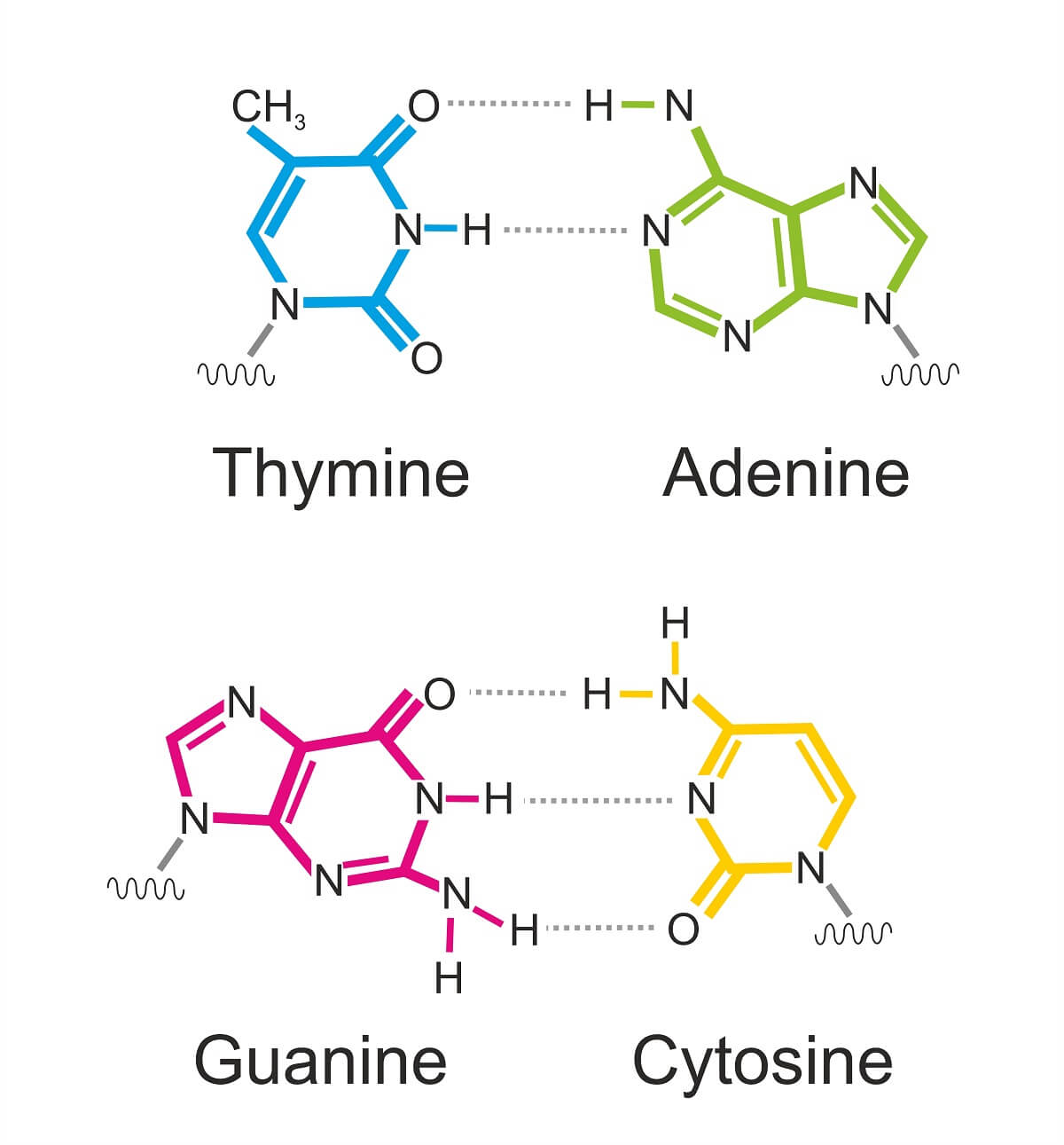
This base pairing is an important mechanism that controls several aspects of DNA and RNA structure. In a DNA molecule, base pairing is the main method that DNA replication takes place. Each new nucleotide base pairs with the nucleotide in front of DNA polymerase, which fuses it to the growing sugar-phosphate backbone. This process creates two double helices out of one.
Though RNA molecules are created in a similar fashion, the ribose sugar backbone and the uracil nucleotides use create slightly less stable hydrogen bonding between base pairs. This allows the RNA molecule to leave the nucleus as a single strand. However, certain sequences, such as those that have evolved to be tRNA molecules, have a specific sequence of nucleotides that can base-pair with each other if folded into the right shape. RNAs with tertiary shapes such as this serve a number of roles within cells.
Let’s turn our attention to the structure of DNA and RNA on a higher level – chromosomes. Chromosomes are made up of many genes, and each gene contains a large number of nucleotide base pairs (somewhere between a few thousand and a few million, depending on the gene). Each gene is made up of exons (the coding regions that carry genetic data) and introns (non-coding regions that separate exons). The purpose of introns is not well established, but many genes have a far greater number of nucleotides within introns than exons. As these genes are transcribed into RNA and processed into mRNA, the introns will be removed – a process covered in our video on section 6.3.
These genes are all connected together into a long sequence. Considering that the human genome contains around 20,000 genes made up of 3.2 billion base pairs, this is an extremely long strand of DNA. Stretched out end-to-end, these genes would be nearly 6 feet long.
However, DNA is wrapped around protein complexes called histones to create nucleosomes. Much like wrapping up a ball of yarn, this greatly reduces the length of each chromosome.
Further, these nucleosomes pack tightly together into a complex structure that further condenses the DNA into a structure called a chromatin fiber. Chromatin can be packed together into a very dense structure, which is how we can see the individual chromosomes during mitosis and meiosis. During interphase of the cell cycle, the chromosomes relax into a loose structure, so that the DNA can be transcribed into RNA and replicated in preparation for the next cell division.
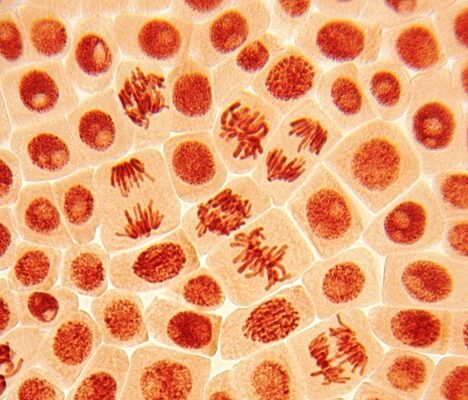
Chromosomes like this that use histones to compact themselves are known as linear chromosomes and are seen mostly in eukaryotic organisms. By contrast, most prokaryotes use a much smaller circular chromosome. While we often depict them together, in reality, a linear chromosome is many times larger than a circular chromosome and typically carries many more genes. We also typically depict chromosomes in an X-shape, but this is not always accurate. First off, the X-shape represents a duplicated chromosome – two sister chromosomes bound at the centromere. Furthermore, the centromere of linear chromosomes is not always located in the middle of the chromosome – it can be at the top or closer to one end than the other.
Finally, let’s take a quick look at prokaryote genomes. While most prokaryotes reproduce asexually and have only a single circular chromosome (which limits genetic variation), most prokaryotic organisms can also exchange small, circular units of DNA known as plasmids.
A plasmid is a chunk of DNA that can contain as little as one gene, making it much smaller than the main circular chromosome of a prokaryote. These plasmids may carry genes that help a bacteria survive. Since many bacterial cells benefit when they live in colonies that can create biofilms and other defensive mechanisms, bacterial cells gain a measure of fitness when they can help other bacteria survive. Bacterial cells can share the genes carried in plasmids through the parasexual reproduction method of bacterial conjugation.
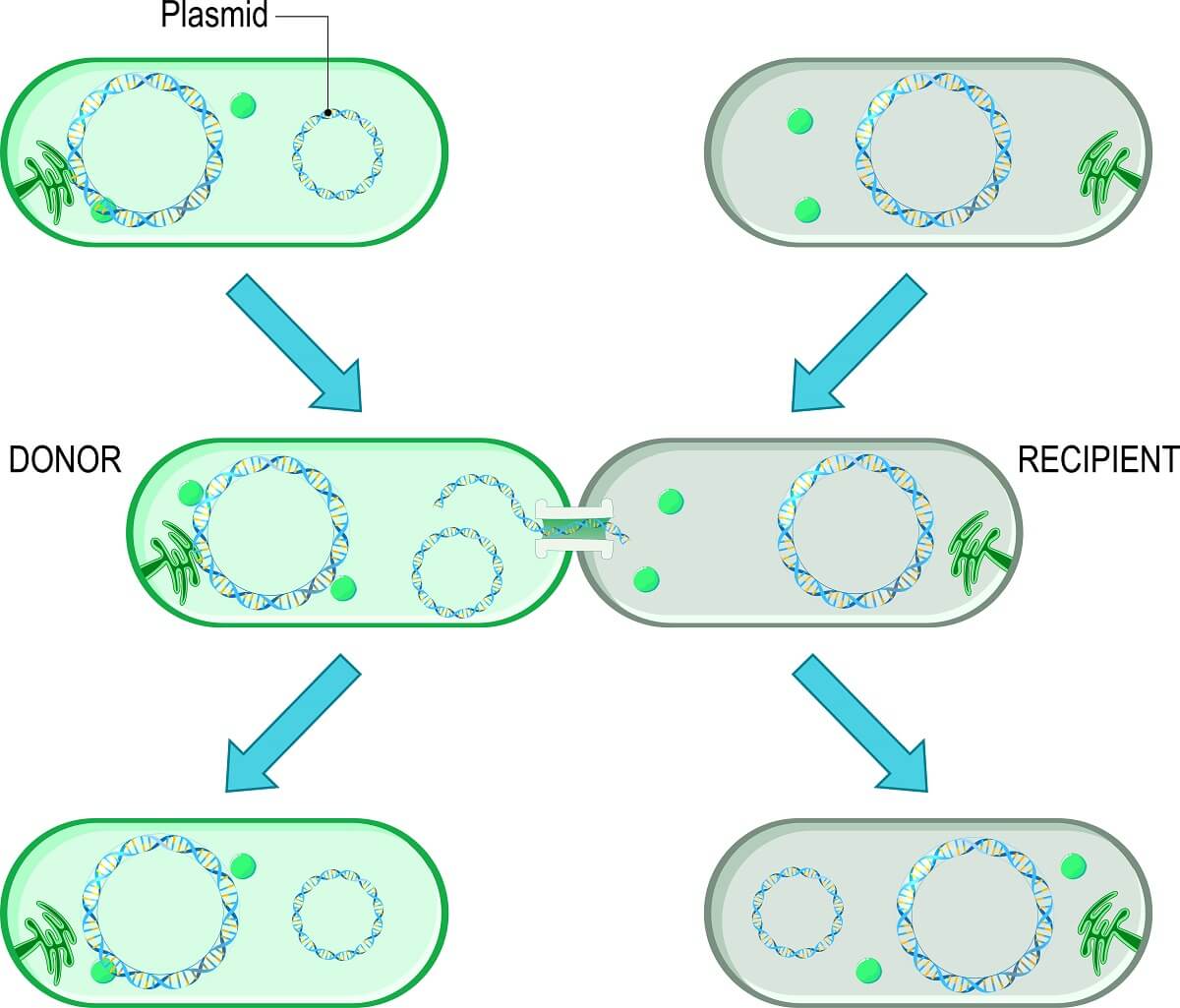
During this process, the plasmid is replicated. Then, it is passed through a channel between the two bacterial cells. Plasmids are known to carry many important genes – such as those that confer antibiotic resistance or an enzyme necessary to process a particular food source. By passing these genes to another bacterial cell, the bacterium can greatly increase how quickly a colony is formed, protecting itself in the process.
However, scientists can also use plasmids to place certain genes within bacterial cells. By modifying a plasmid to contain pieces of foreign DNA (called recombinant DNA because it is from different species), scientists can put almost any gene they want into a bacterial colony. The plasmids are created, bacteria heated up and cooled down to help the plasmid slip through the cell membrane, and some of the bacteria take up and successfully express the genes contained in the plasmid. When they reproduce, they can carry this new gene with them.
In a simple example, scientists were able to take normal E. coli bacteria, and introduce a gene that causes fluorescence in jellyfish. When this plasmid is successfully incorporated into a colony, the whole colony glows green. But, this can also be used for more important reasons than just getting bacteria to glow – human insulin (an important protein hormone used as medicine by people with diabetes) is produced by bacteria that have been transformed with recombinant DNA!